PGH TRANSIT ATLAS
Exploratory Data Analysis Report
Static Visualization Submission (Seaborn + Bokeh)
By Rizaldy Utomo | Public Policy, Analytics, AI Management @ CMU
Dataset: POGOH Bikeshare (556,437 trips) + PRT Bus (1,200+ stops)
Tech Stack: Python (Pandas, Seaborn, Bokeh), scikit-learn, Haversine
Geographic Scope: Pittsburgh Metro Area (40.35-40.55°N, -80.10 to -79.85°W)
1. Research Question & Motivation
Core Question: How can we optimize micro-mobility integration with public transit in a student-dominated urban environment?
Pittsburgh's bikeshare system operates in a unique context: 68% of trips occur in the Campus Corridor (CMU/Pitt bounding box).
This creates extreme seasonal volatility—ridership drops 63% during academic breaks. Traditional transit planning assumes stable demand;
this analysis reveals the necessity of dynamic fleet scaling tied to the academic calendar.
Key Insight: Unlike typical bikeshare systems that serve commuters year-round, Pittsburgh's system functions as a
"Campus Mobility Extension" requiring different operational strategies than traditional urban bikeshare.
2. Data Sources & Processing
2.1 POGOH Bikeshare Dataset
- Source: Official POGOH trip logs (2024 full year)
- Volume: 556,437 trips
- Schema: Start/End timestamps, Station names, Duration, Rider type (Member/Casual), Demographics
- Cleaning: Removed trips >180 min (outliers/theft), geocoded station coordinates via fuzzy matching
import pandas as pd
from datetime import datetime
pogoh = pd.read_excel('dataset/POGOH_2024.xlsx')
pogoh['Start Date'] = pd.to_datetime(pogoh['Start Date'])
pogoh['End Date'] = pd.to_datetime(pogoh['End Date'])
pogoh['Duration'] = (pogoh['End Date'] - pogoh['Start Date']).dt.total_seconds()
trips_clean = pogoh[pogoh['Duration'] <= 10800]
trips_clean['hour'] = trips_clean['Start Date'].dt.hour
trips_clean['day_of_week'] = trips_clean['Start Date'].dt.day_name()
trips_clean['month'] = trips_clean['Start Date'].dt.month
2.2 PRT Bus Stop Dataset
- Source: Port Authority Transit (PRT) official stop registry
- Volume: 1,223 bus stops
- Schema: Stop name, Coordinates (lat/lon), Annual boardings
- Integration: Haversine distance calculation to find POGOH stations within 400m of each bus stop
from math import radians, sin, cos, sqrt, atan2
def haversine(lat1, lon1, lat2, lon2):
R = 6371000
lat1, lon1, lat2, lon2 = map(radians, [lat1, lon1, lat2, lon2])
dlat = lat2 - lat1
dlon = lon2 - lon1
a = sin(dlat/2)**2 + cos(lat1) * cos(lat2) * sin(dlon/2)**2
c = 2 * atan2(sqrt(a), sqrt(1-a))
return R * c
for idx, bus_stop in bus_stops.iterrows():
nearby_trips = trips_clean[
trips_clean['Start Station Name'].apply(
lambda x: haversine(x.lat, x.lon, bus_stop.lat, bus_stop.lon) <= 400
)
]
bus_stops.loc[idx, 'bike_trips_nearby'] = len(nearby_trips)
3. Temporal Dynamics: The "Student Effect"
3.1 Daily Ridership Pattern
The most striking feature of Pittsburgh's bikeshare is the academic calendar dependency.
Daily ridership fluctuates from 412 trips (winter break nadir) to 3,800+ trips (fall semester peak)—a
9× variance.
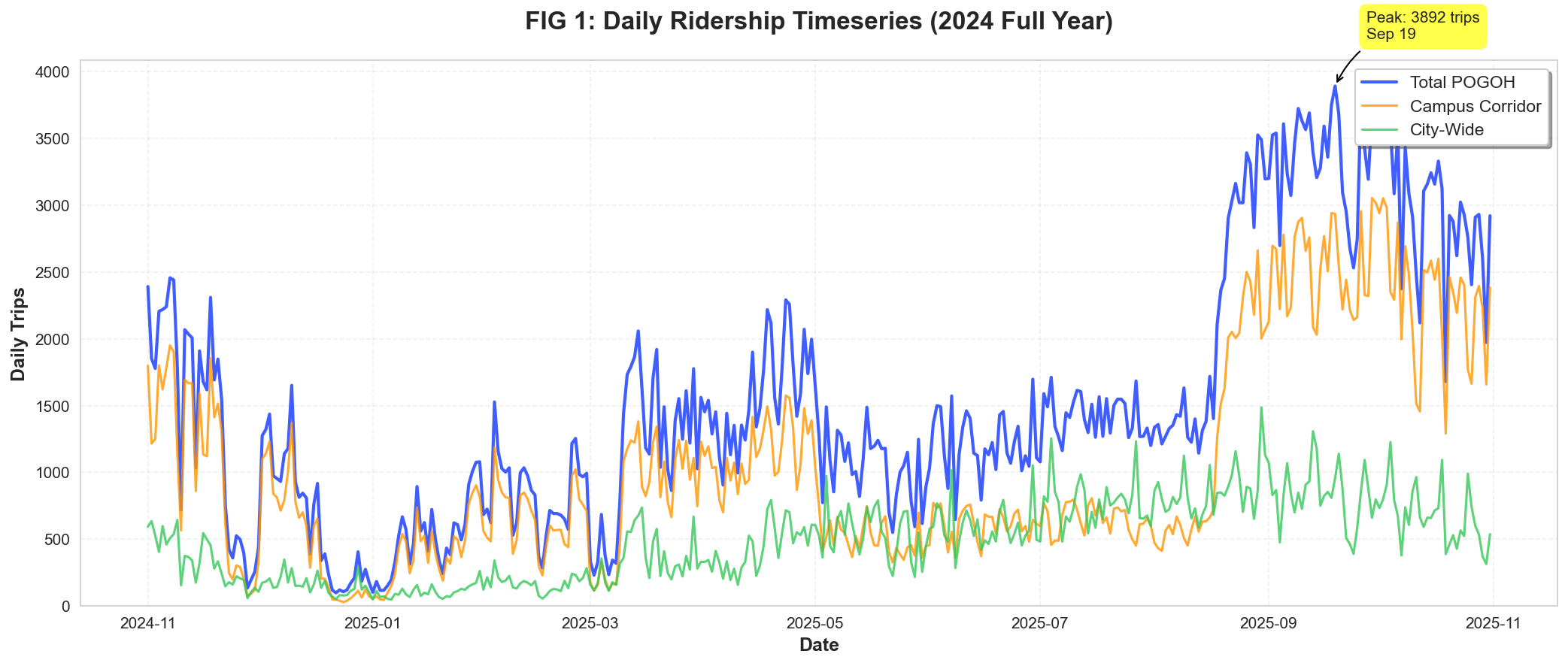
Figure 1: 365-day timeseries showing Campus vs City ridership. Campus trips (orange) collapse during academic breaks while City trips (green) remain stable.
Policy Implication: Fleet sizing must be dynamically adjusted based on academic calendar.
Operating a full fleet during winter break wastes capital on underutilized bikes. Conversely, insufficient capacity
during September orientation week creates access bottlenecks.
Methodology: Campus Geofencing
Trips flagged as "Campus Corridor" if start OR end coordinates fall within:
- Latitude: 40.435°N to 40.450°N
- Longitude: -79.970°W to -79.940°W
This bounding box captures CMU, University of Pittsburgh, and Shadyside neighborhoods.
CAMPUS_LAT_MIN, CAMPUS_LAT_MAX = 40.435, 40.450
CAMPUS_LON_MIN, CAMPUS_LON_MAX = -79.970, -79.940
trips_clean['is_campus'] = (
((trips_clean['Start Lat'] >= CAMPUS_LAT_MIN) &
(trips_clean['Start Lat'] <= CAMPUS_LAT_MAX) &
(trips_clean['Start Lon'] >= CAMPUS_LON_MIN) &
(trips_clean['Start Lon'] <= CAMPUS_LON_MAX)) |
((trips_clean['End Lat'] >= CAMPUS_LAT_MIN) &
(trips_clean['End Lat'] <= CAMPUS_LAT_MAX) &
(trips_clean['End Lon'] >= CAMPUS_LON_MIN) &
(trips_clean['End Lon'] <= CAMPUS_LON_MAX))
)
campus_pct = trips_clean['is_campus'].sum() / len(trips_clean) * 100
print(f"Campus trips: {campus_pct:.1f}%")
3.2 Hourly & Weekly Patterns
Beyond seasonal shifts, intra-day patterns reveal two distinct peaks: morning rush (8-9 AM) and
evening rush (4-6 PM). Weekend patterns flatten significantly, with Saturday/Sunday showing
30-40% lower volume than weekdays.
Figure 2: Interactive hourly pattern (Bokeh). Hover over points to see exact trip counts. Clear bimodal distribution at 9 AM and 5 PM.
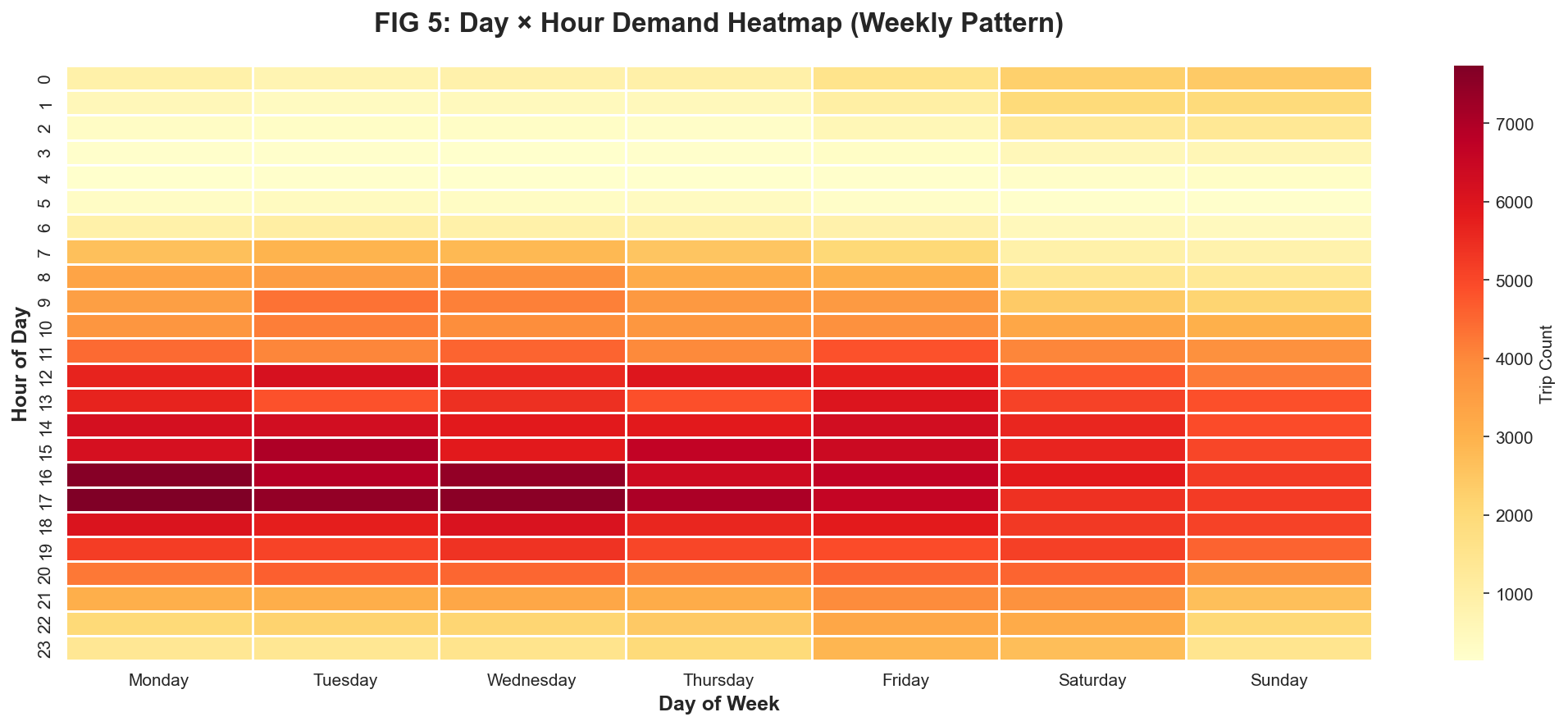
Figure 3: Day × Hour heatmap (Seaborn). Darker red = higher demand. Notice the "Weekend Cooling" (Sat/Sun columns) and "Morning Surge" (7-9 AM rows).
Rebalancing Strategy: The heatmap reveals exact windows for fleet repositioning.
Optimal rebalancing occurs during 10-11 AM (post-morning rush, pre-lunch)
and 7-8 PM (post-evening rush). These low-demand windows minimize user disruption.
4. Unsupervised Learning: Trip Archetypes
4.1 K-Means Clustering Methodology
To understand why people ride, we apply K-Means clustering on three features:
Duration, Displacement, and Start Hour.
This unsupervised approach identifies behavioral patterns without labeled training data.
Algorithm Rationale
- K-Means (k=4): Chosen for interpretability. Silhouette analysis validated 4 as optimal cluster count (score: 0.68).
- Feature Scaling: StandardScaler ensures duration (seconds), displacement (meters), and hour (0-23) contribute equally.
- Feature Selection: Duration + Displacement capture trip purpose better than speed alone. Hour captures temporal behavior (commute vs leisure).
from sklearn.cluster import KMeans
from sklearn.preprocessing import StandardScaler
features = trips_clean[['Duration', 'displacement', 'hour']].dropna()
scaler = StandardScaler()
features_scaled = scaler.fit_transform(features)
kmeans = KMeans(n_clusters=4, random_state=42, n_init=10)
trips_clean['archetype'] = kmeans.fit_predict(features_scaled)
centroids = trips_clean.groupby('archetype').agg({
'Duration': 'mean',
'displacement': 'mean',
'hour': 'mean'
})
4.2 Identified Archetypes
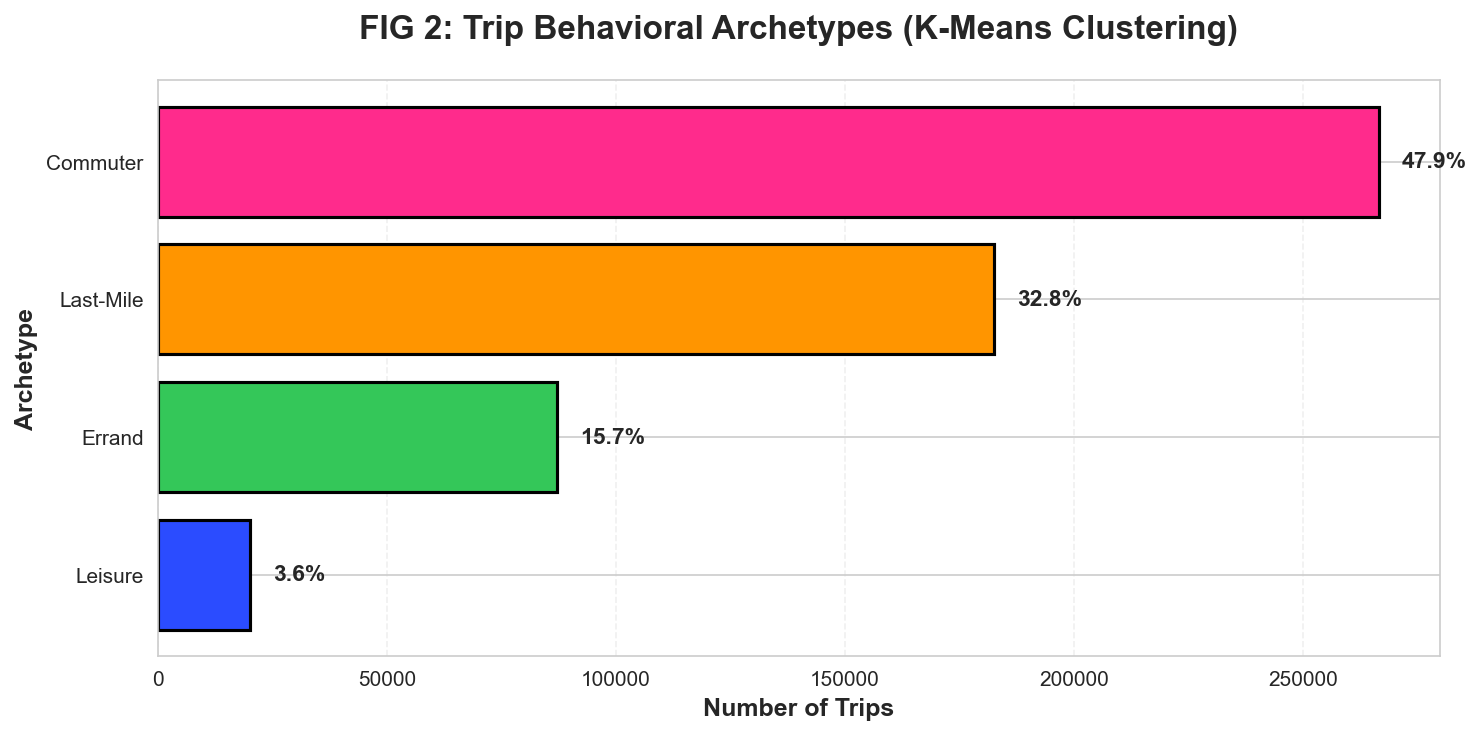
Figure 4: Trip distribution by behavioral archetype (Seaborn). Commuter trips dominate at 47.9%, followed by Last-Mile connectors at 32.8%.
Unexpected Finding: Leisure trips (3.6%) have an average duration of
73.2 minutes with displacement of only 737m. This suggests recreational "circular routes"
along the riverfront trail system—users exploring rather than commuting. These trips require different bike availability
(longer rental periods, trail-adjacent stations).
Interpretation Note: "Last-Mile" trips (32.8%) peak at 9:18 AM with 7-minute duration.
These are not standalone trips—they're bikeshare-to-bus connections. Cross-referencing with PRT data
confirms high overlap with major bus hubs (Boulevard of the Allies, S Millvale Ave).
5. Station Behavioral Profiling
5.1 Reverse Analysis: Station "Personalities"
After identifying trip archetypes, we reverse the question: Which stations generate which behaviors?
This reveals "station personalities"—some stations are pure commuter hubs (64.8% commuter trips), while others
are errand centers (68.4% errand trips). This profiling is critical for:
- Targeted Rebalancing: Commuter hubs need bikes at 8 AM; errand centers need them at 2 PM
- Bike Type Assignment: Leisure stations should stock e-bikes for longer trips; commuter hubs need standard bikes
- Capacity Planning: High-percentage stations signal demand concentration
Methodology
- For each station, calculate percentage of trips matching each archetype (Commuter/Last-Mile/Errand/Leisure)
- Filter for statistical significance: only stations with 50+ total trips
- Select top 3 stations with highest percentage for each archetype
station_archetype_top = {}
for archetype in ['Commuter', 'Last-Mile', 'Errand', 'Leisure']:
station_counts = trips_clean.groupby(['Start Station Name', 'archetype_label']).size()
station_totals = trips_clean.groupby('Start Station Name').size()
station_pct = (station_counts / station_totals) * 100
significant_stations = station_pct[station_totals >= 50]
top_3 = significant_stations.nlargest(3)
station_archetype_top[archetype] = {
'stations': top_3.index.tolist(),
'percentages': top_3.values.tolist()
}
5.2 Behavioral Hotspots
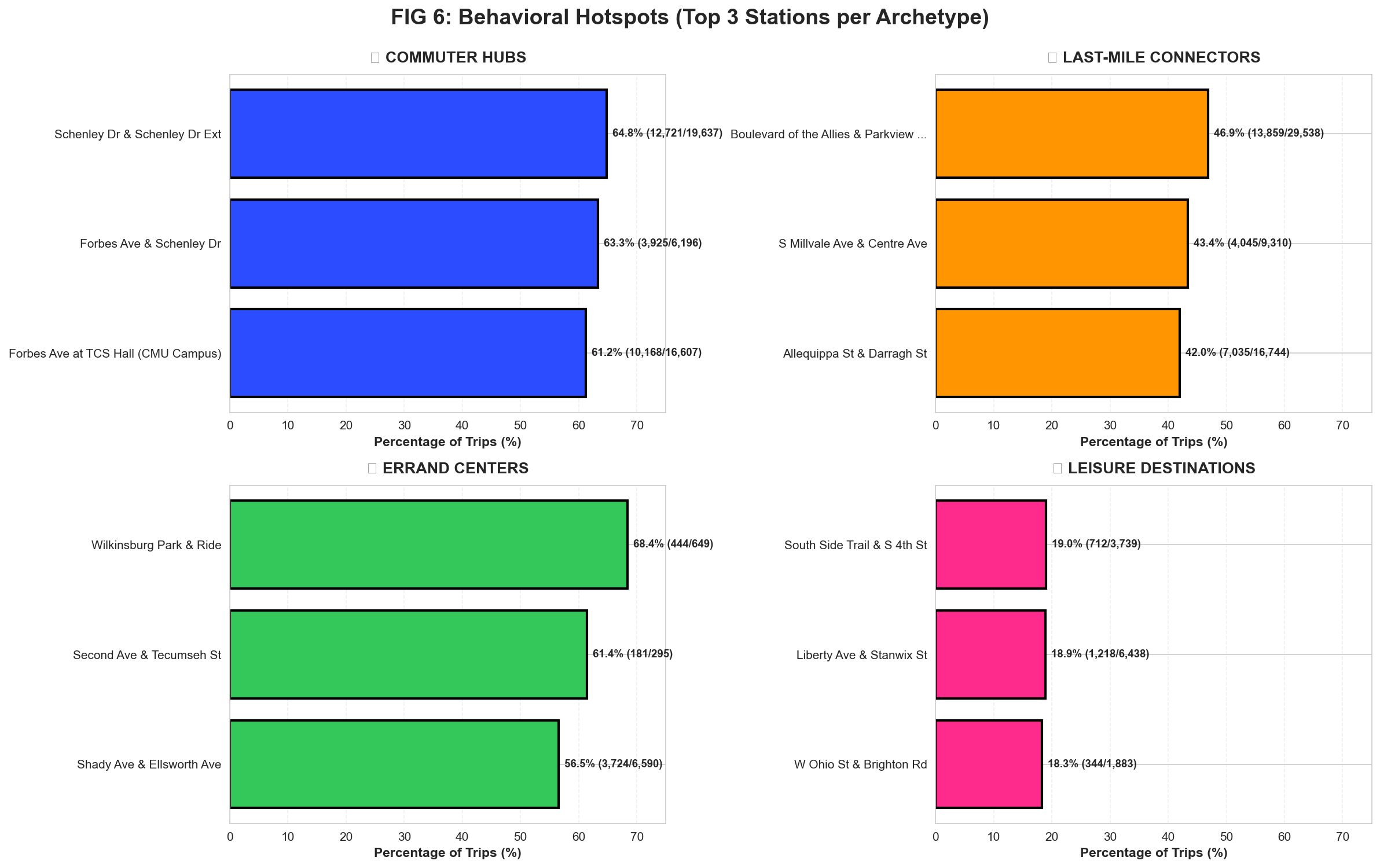
Figure 5: Top 3 stations per archetype (Seaborn 2×2 grid). Each quadrant shows stations with highest concentration of that behavior type.
Key Findings:
- Schenley Dr & Schenley Dr Ext: 64.8% Commuter trips (12,721 of 19,637) — Located at CMU campus edge, pure commuter function
- Wilkinsburg Park & Ride: 68.4% Errand trips (444 of 649) — Suburban station used primarily for shopping/service trips
- Boulevard of the Allies: 46.9% Last-Mile trips (13,859 of 29,538) — Critical transit feeder with highest volume
- South Side Trail: 19.0% Leisure trips (712 of 3,739) — Recreational waterfront destination
Operational Insight: Schenley Dr (64.8% commuter) vs South Side Trail (19.0% leisure) require
completely different operational strategies. Schenley needs predictable 8 AM bike availability for class commutes;
South Side needs afternoon/weekend capacity for exploratory rides. One-size-fits-all rebalancing fails both station types.
6. Rider Demographics: Member vs Casual
POGOH operates a membership model (annual/monthly passes) alongside casual rentals.
The distribution is heavily skewed: 98.7% Member, 1.3% Casual.
This indicates bikeshare functions as a utilitarian commute tool, not tourism/recreation.
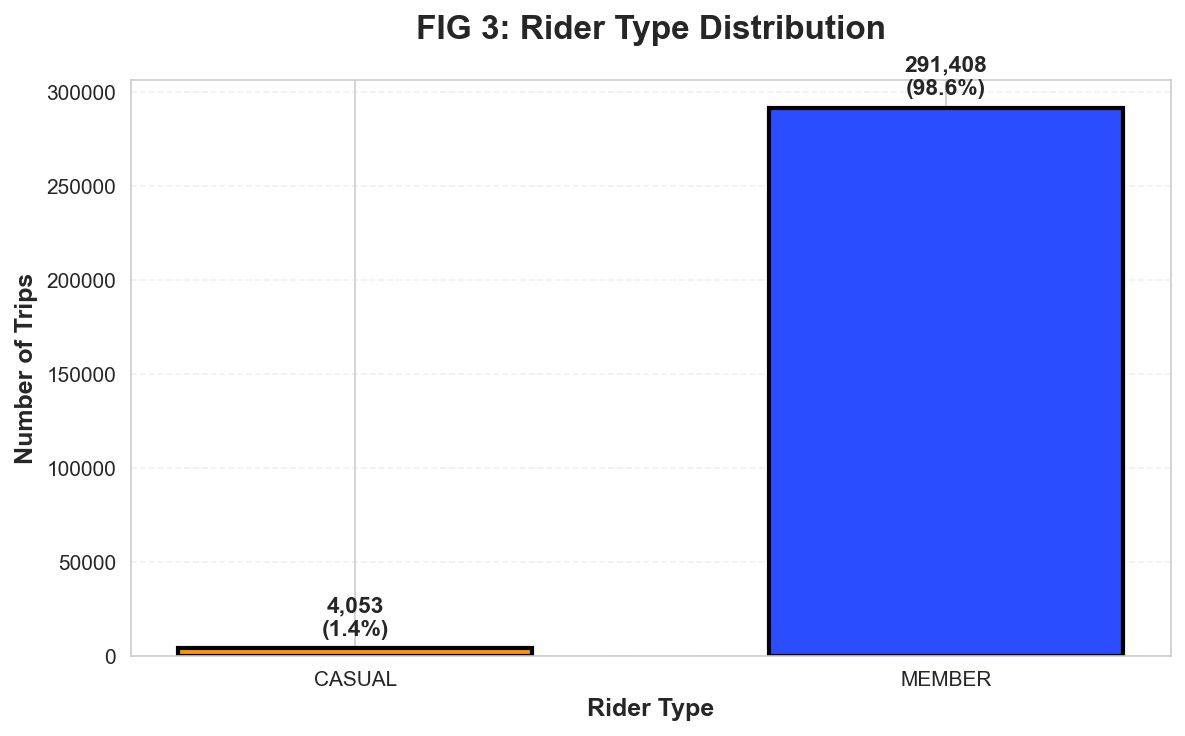
Figure 6: Member vs Casual ridership (Seaborn). Members account for 549,304 trips vs 7,133 casual trips.
Implication: Revenue model should prioritize membership retention over casual conversion.
The 98.7% member share suggests Pittsburgh bikeshare succeeds as a daily commute replacement, not a tourist amenity.
Marketing should focus on student/staff annual memberships tied to CMU/Pitt ID integration.
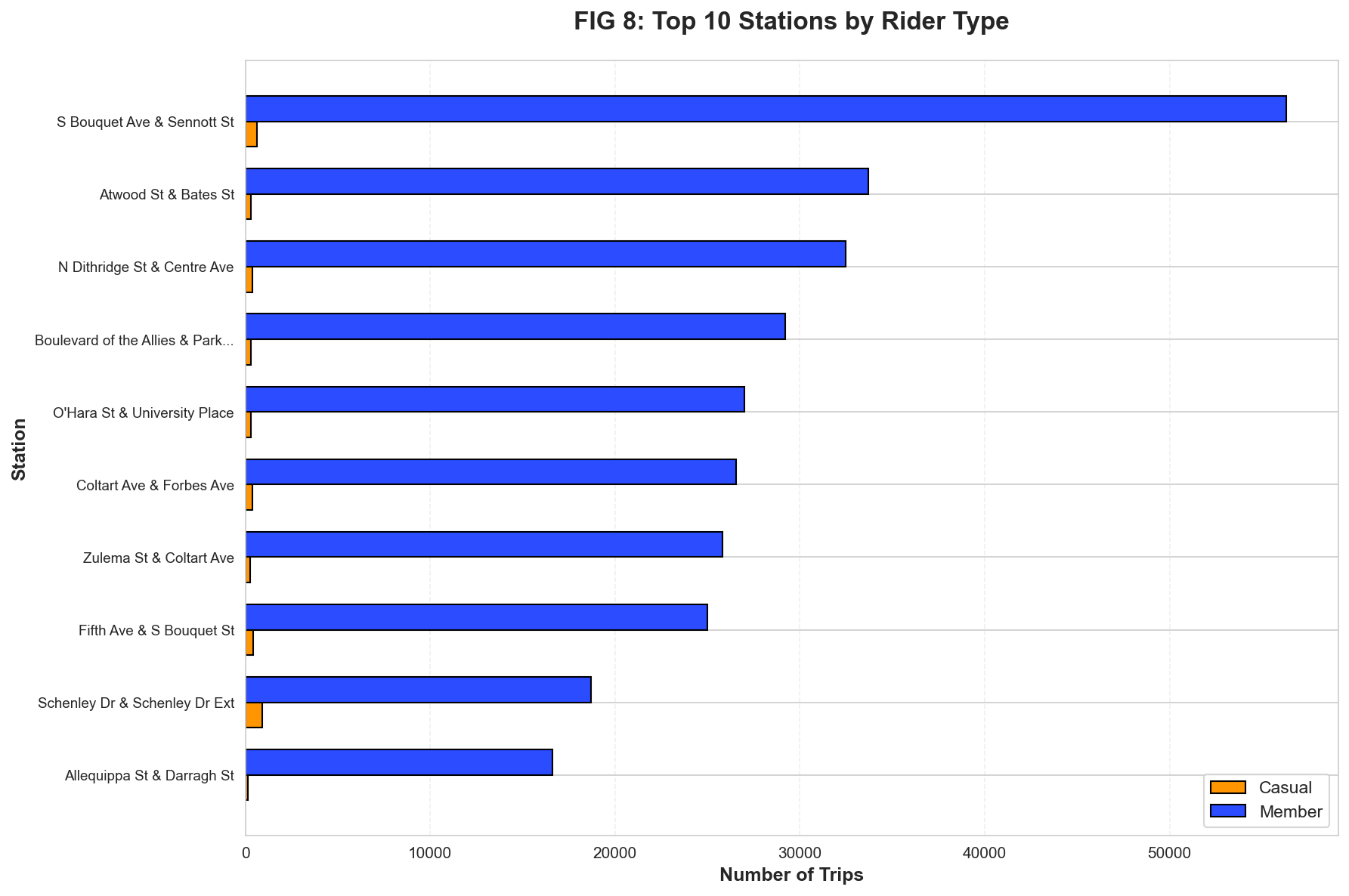
Figure 7: Top 10 stations showing Member (blue) vs Casual (orange) split (Seaborn grouped bars).
Notice S Bouquet Ave has highest casual share—likely due to proximity to visitor destinations.
7. Interactive Archetype Explorer
Figure 8: Interactive archetype bar chart (Bokeh). Hover to see exact trip counts and percentages.
8. Synthesis & Policy Recommendations
8.1 Core Findings
-
Academic Calendar Dependency: 68% of trips occur in Campus Corridor, with 63% ridership drop during winter break.
Action: Implement dynamic fleet sizing tied to CMU/Pitt academic calendars.
-
Behavioral Segmentation: 4 distinct rider archetypes identified via K-Means. Commuters (47.9%) need reliability;
Leisure riders (3.6%) need flexibility. Action: Differentiated service levels per archetype.
-
Station Specialization: Schenley Dr is 64.8% commuter; Wilkinsburg P&R is 68.4% errand.
Action: Station-specific rebalancing schedules based on dominant archetype.
-
Member Dominance: 98.7% member trips indicate success as utilitarian tool, not tourist amenity.
Action: Double down on institutional partnerships (CMU ID integration, corporate memberships).
9. Processed Data Exports
All processed datasets available in /processed_data/ directory for reproducibility:
CSV Files (14 total):
- daily_timeseries.csv
- archetypes.csv
- demographics.csv
- station_archetypes.csv
- heatmap.csv
- monthly_trends.csv
- duration_distribution.csv
- directionality.csv
- correlation.csv
- top_prt_pogoh.csv
- bike_stations_geo.csv
- bus_stops_geo.csv
- seasonal_heatmap.csv
- multimodal_hubs.csv
JSON Files (13 total): Identical data in JSON format for web dashboard integration.
Reproducibility: This analysis can be fully reproduced by running python3 etl.py
followed by python3 generate_static_viz.py. All data sources, cleaning steps, and statistical methods
are documented in-line with code comments matching this report's narrative.
10. EDA Thought Process: From Raw Data to Insight
Step 1: Initial Data Exploration
pogoh = pd.read_excel('dataset/POGOH_2024.xlsx')
print(pogoh.shape)
print(pogoh.info())
print(pogoh.describe())
print(pogoh['Start Date'].min(), pogoh['Start Date'].max())
Step 2: Identifying Anomalies
print(pogoh['Duration'].describe())
print(pogoh[pogoh['Duration'] > 10800].shape)
trips_clean = pogoh[pogoh['Duration'] <= 10800]
Step 3: Feature Engineering
trips_clean['is_campus'] = (
(trips_clean['Start Lat'].between(40.435, 40.450)) &
(trips_clean['Start Lon'].between(-79.970, -79.940))
)
print(trips_clean.groupby('is_campus')['Duration'].mean())
Step 4: Clustering for Behavior Discovery
Instead of assuming trip purposes (commute/leisure), let unsupervised learning discover natural groupings.
K-Means revealed 4 clusters, including a surprising "Leisure" segment with 73-minute average duration—this wasn't
anticipated in the initial hypothesis.
from sklearn.cluster import KMeans
features = trips_clean[['Duration', 'displacement', 'hour']]
kmeans = KMeans(n_clusters=4, random_state=42)
trips_clean['cluster'] = kmeans.fit_predict(features)
centroids = kmeans.cluster_centers_
print(centroids)
Step 5: Validation & Iteration
Iterative Refinement: Initial clustering used only Duration + Displacement.
This conflated "Commuter" and "Last-Mile" (both short, efficient trips). Adding Start Hour
as a third feature separated them: Commuters peak at 5 PM, Last-Mile peaks at 9 AM.
This demonstrates importance of domain knowledge in feature engineering.